
A legtöbb cég csak álmodik egy olyan elektronikus archívumról, amelyben a szövegre is lehet keresni. A 30%-a a cégeknek azért keres szövegfelismerő szoftver rendszert, hogy digitalizálni tudja a régebbi anyagait. Nézzük meg akkor, hogyan kell a dokumentumokat egy ilyen archívumba bevinni, hogy amellett hogy másodpercek alatt megtalálhatók legyenek, még jól is nézzenek ki?
A dokumentumok egy része gyengén lett szkennelve, vagy csak túl öreg, s ezért így néz ki:

De a legújabb FineReader 12 segítségével ez lehet ilyen minőségű is:

Ugyanis az ABBYY FineReader 12 képes megszüntetni a régi anyagok besárgult színét, vagy a gyengén szkennelt részek szürke tónusát, miközben a betűket kisimítja.
Nézzük meg, milyen egyszerűen is megy ez:
1. Győződjünk meg, hogy a „Szöveg az oldalkép alatt”
![]() van kiválasztva és az „Az ABBYY PreciseScan alkalmazása a képeken lévő karakterek simításához”
van kiválasztva és az „Az ABBYY PreciseScan alkalmazása a képeken lévő karakterek simításához”
![]() opció be van jelölve a Mentés -> PDF (PDF/A) fülön a Beállításokban.
opció be van jelölve a Mentés -> PDF (PDF/A) fülön a Beállításokban.![]()
2. Ezután mehet vagy a szkennelés vagy megnyithatjuk a dokumentum képét vagy az elektronikusan érkezett PDF-t.
3. Ha a háttér nem elég fehér kattintsunk a képszerkesztés
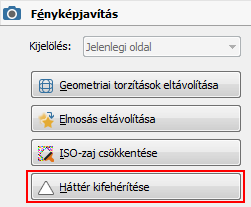
Majd lépjünk ki a képszerkesztőből.
![]()
4. Válasszuk a Mentés PDF dokumentumként vagy Mentés PDF/A dokumentumként menüpontot.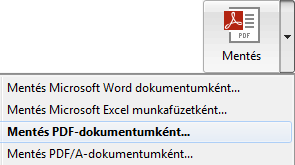
Ha esetleg még felugrik egy ablak, válasszuk a „Felismerés és mentés” gombot.
Már kész is van! A szövegesen kereshető dokumentum elkészült. Ez teljesen megegyezően vagy még jobban is néz ki, mint az eredeti, – köszönhetően a PreciseScan technológiának és a Háttér kifehérítésnek.